
Toda decisión de contratación apoyada en una prueba psicométrica descansa sobre dos preguntas que rara vez se le hacen al proveedor que la vende: ¿cómo sabemos que esta prueba mide lo que dice medir, y con qué precisión lo hace?
Este documento explica por qué validez y confiabilidad son los únicos indicadores reales de calidad en psicometría, y por qué la mayoría de las pruebas que se aplican hoy en México no tienen esa evidencia documentada para población mexicana.
Está dirigido a decisores informados: personas que toman decisiones sobre el talento de su organización todos los días y que merecen entender la herramienta que están usando, sin que se les pida confiar a ciegas en el prestigio histórico de un nombre.
Lo que encontrarás en las páginas siguientes: el marco que utilizan los estándares internacionales (APA, AERA, ITC) para evaluar la seriedad de un instrumento; los umbrales numéricos concretos que la literatura ha fijado como mínimos aceptables; evidencia documentada sobre el riesgo técnico y legal de usar pruebas no validadas para población mexicana; y un checklist de catorce preguntas que cualquier comprador debería poder hacerle a su proveedor de psicometría.
En Psicotest llamamos a esto contratar con ciencia. Y la ciencia, cuando es seria, se puede demostrar.
Casi todos los proveedores de psicometría laboral en México afirman lo mismo: que sus pruebas miden personalidad, liderazgo, inteligencia, potencial. Cada uno con su repertorio de palabras y de prestigio histórico. Pocos se molestan en responder la pregunta que importa: ¿cómo sabemos que efectivamente lo miden?
Esta pregunta no es retórica ni filosófica. Tiene una respuesta técnica precisa, y se llama validez.
Los Standards for Educational and Psychological Testing — el marco normativo internacional vigente, elaborado conjuntamente por la American Educational Research Association, la American Psychological Association y el National Council on Measurement in Education (AERA, APA y NCME, 2014) — definen la validez como “el grado en que la evidencia y la teoría sustentan las interpretaciones de las puntuaciones de un test para los usos propuestos”.
Esa definición esconde dos ideas que cambian todo lo que tradicionalmente se cree sobre las pruebas psicométricas.
Primera idea: la validez no es una propiedad del test
La validez es una propiedad de la interpretación que se hace de las puntuaciones, para un uso específico, en una población específica. Un mismo instrumento puede ser válido para un propósito e inválido para otro. Puede ser válido en Boston y dudoso en Monterrey. Puede haber sido válido en 1995 y no serlo hoy.
Como advierten Prieto y Delgado (2010), en Papeles del Psicólogo: “un frecuente malentendido consiste en considerar que la fiabilidad y la validez son características de los tests; por el contrario, corresponden a propiedades de las interpretaciones, inferencias o usos específicos de las medidas”.
Segunda idea: la validez no es un certificado, es un argumento
Samuel Messick (1989) y posteriormente Michael Kane (2013) construyeron lo que hoy se conoce como el enfoque argumentativo de la validación. La idea es simple y demoledora: validar un test no consiste en obtener un sello que diga “ya está validado”, sino en construir y mantener vivo un argumento que conecte cada eslabón del proceso — desde la respuesta a un ítem hasta la decisión final de contratación — con evidencia empírica acumulada.
Si un eslabón se rompe (la muestra deja de representar a la población actual, los criterios laborales cambian, la cultura del país evoluciona), el argumento de validez se rompe con él. Por eso, en psicometría rigurosa, “validar” es un verbo en presente continuo. Nunca pasado.
Existe una forma de validez que vende sin demostrar nada: la validez aparente o face validity. Es el grado en que un test parece — al ojo del candidato o del decisor — apropiado para lo que dice medir. Si las preguntas hablan de liderazgo, asumimos que mide liderazgo. Si tiene un cuestionario denso y un puntaje al final, asumimos que es serio.
La trampa es que la apariencia de relevancia no predice nada sobre el valor predictivo real. Instrumentos con altísima validez aparente — entrevistas no estructuradas, por ejemplo — pueden tener coeficientes de predicción del desempeño laboral considerablemente menores que instrumentos que parecen abstractos o poco intuitivos (Sackett, Zhang, Berry y Lievens, 2022).
La validez aparente es a la validez real lo que la decoración es a la estructura: puede dar confianza, pero no sostiene una decisión.
La validación es el proceso continuo de acumulación de evidencia que sostiene la interpretación de las puntuaciones de un test. No es un certificado emitido una sola vez. Es un argumento que debe construirse, mantenerse y actualizarse — y que puede romperse cuando la población cambia, cuando el contexto laboral cambia, o cuando pasa el tiempo sin re-normalización.
La validez no es un solo bloque. Es un conjunto articulado de evidencias, cada una con su propio método y su propio criterio. Un proveedor serio debe poder demostrar todas las que apliquen al uso que vende.
La validez de contenido evalúa si los ítems del test cubren adecuadamente el dominio conceptual de aquello que dice medir. En selección de personal, esto se traduce en una pregunta concreta: ¿los ítems se diseñaron a partir de un análisis del puesto real?
El Estándar 11.2 de los AERA/APA/NCME (2014) exige “una definición minuciosa y explícita del dominio de contenido de interés” antes de construir cualquier ítem. La evidencia mínima exigible incluye análisis de puesto documentado, revisión por expertos independientes, y matriz de especificaciones que vincule cada ítem con un componente del constructo medido.
Si un proveedor no puede mostrar este trabajo, su test mide lo que el autor original imaginó — no lo que tu organización necesita predecir.
La validez de constructo es la más exigente. Evalúa si el test mide efectivamente el atributo psicológico que dice medir (liderazgo, conciencia, estabilidad emocional) y no otra cosa. Se demuestra con métodos estadísticos específicos:
La validez de criterio mide la relación entre el puntaje del test y un criterio externo relevante — en selección de personal, casi siempre el desempeño laboral. Tiene dos formas:
Los rangos de coeficientes considerados aceptables — referidos a la correlación entre el puntaje del test y el desempeño medido posteriormente — son los siguientes, según la guía del U.S. Department of Labor:
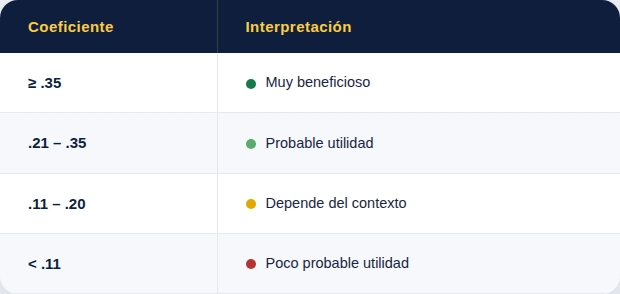
La revisión metaanalítica más reciente — Sackett y colaboradores (2022) en Journal of Applied Psychology — reporta las siguientes estimaciones revisadas (corregidas por restricción de rango directa) para los procedimientos de selección más comunes:
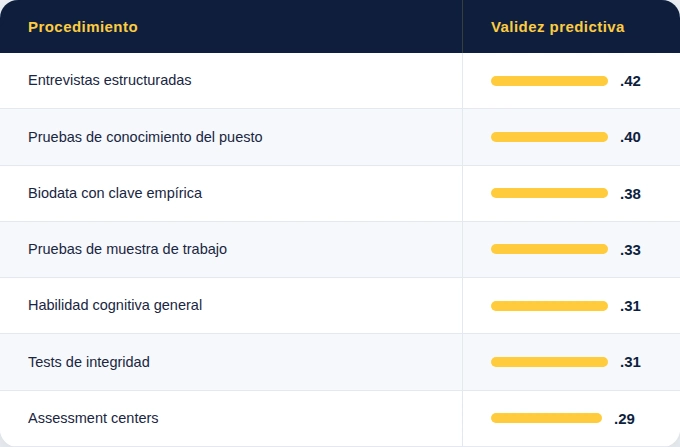
Estos valores son entre .10 y .20 puntos menores que los reportados durante décadas por Schmidt y Hunter (1998), debido a correcciones metodológicas. La traducción al mercado es directa: durante mucho tiempo se vendieron instrumentos con coeficientes sobreestimados, y la corrección académica ha sido reciente. Si tu proveedor todavía cita los valores de 1998, está usando una versión desactualizada del conocimiento disponible.
Dos formas de validez menos discutidas pero esenciales:
Aquí entramos en el problema técnico más subestimado del mercado mexicano. La validez transcultural se refiere a si un instrumento desarrollado en una cultura mantiene sus propiedades psicométricas cuando se aplica en otra.
Byrne y colaboradores (2009), en Training and Education in Professional Psychology, advierten: “la administración no crítica de instrumentos occidentales a clientes no-occidentales puede llevar a inferencias incorrectas”. La International Test Commission (2017) lo dice todavía más claro: traducir un test no es adaptarlo. La traducción es solo lengua; la adaptación implica revisar la equivalencia del constructo, modificar formatos donde sea necesario, pilotar, y revalidar completamente sobre la población destino.
Tres ejemplos que importan al mercado mexicano:
Tres pruebas de uso común en el mercado mexicano — Terman-Merrill, Gordon Personal Profile y Kostick PAPI — no cuentan con estudios publicados de revalidación con muestras representativas mexicanas contemporáneas. Aplicarlas sin esa evidencia no es psicometría: es una hipótesis con costo de contratación.
La confiabilidad — o fiabilidad, según la tradición que se siga — es la consistencia de la medición. La pregunta que responde es distinta a la de la validez: no si el test mide lo correcto, sino si lo mide con precisión.
La relación entre ambas es jerárquica: la confiabilidad es condición necesaria pero no suficiente de la validez. Un test puede ser muy confiable y medir algo irrelevante. Pero un test con baja confiabilidad nunca puede tener alta validez. La confiabilidad pone el techo a lo que la validez puede alcanzar.
El estimador más usado históricamente es el alfa de Cronbach (α). Estima la consistencia interna a partir de las covarianzas entre los ítems del test. Su problema técnico, conocido desde hace décadas pero rara vez mencionado por los proveedores, es que supone tau-equivalencia — es decir, que todos los ítems tienen la misma carga factorial sobre el constructo medido. Este supuesto casi nunca se cumple en pruebas psicométricas reales.
Cuando el supuesto no se cumple, alfa subestima la confiabilidad real.
El estimador que la literatura moderna recomienda en su lugar es el omega de McDonald (ω). No requiere tau-equivalencia y usa las cargas factoriales directamente. Una revisión publicada en Frontiers in Psychology (2016) concluye que “el coeficiente omega es siempre una mejor elección que alfa, y en presencia de ítems asimétricos es preferible usar omega”.
Si tu proveedor solo reporta alfa, está reportando un coeficiente que probablemente subestima la confiabilidad real de su test. Si reporta omega — y mejor aún, ambos — está operando dentro del estándar contemporáneo.
Aquí hay un número que cualquier comprador de psicometría debería conocer.
Prieto y Delgado (2010), en Papeles del Psicólogo, lo establecen sin matices: “cuando las puntuaciones vayan a emplearse para tomar decisiones que impliquen consecuencias relevantes para las personas — por ejemplo, aceptación o rechazo en una selección de personal — el coeficiente de fiabilidad debería ser muy alto: al menos 0.90”.
Para describir diferencias individuales a nivel de grupo (con fines de investigación, por ejemplo), basta con un coeficiente ≥ .70. Pero para decisiones que afectan a una persona — contratar, no contratar, promover, no promover — el umbral académico mínimo es .90. Nunnally (1978) estableció este criterio hace casi cinco décadas, y sigue siendo referencia.
Si tu proveedor reporta coeficientes de confiabilidad entre .70 y .80 y los presenta como suficientes para selección, está aplicando un estándar académico equivocado.
El test-retest mide la estabilidad temporal del constructo: qué tan similares son las puntuaciones de las mismas personas en dos administraciones separadas en el tiempo. Es relevante para constructos estables como inteligencia cristalizada o rasgos de personalidad; menos apropiado para estados emocionales o actitudes, que cambian rápidamente.
Para rasgos de personalidad en selección, el intervalo recomendado es de 2 a 8 semanas. Intervalos más largos confunden cambio real con inestabilidad del instrumento.
Aplica cuando la puntuación depende del juicio de un evaluador humano: entrevistas conductuales, assessment centers, ejercicios situacionales, calificación de ensayos. El índice estándar es el kappa de Cohen (κ), que corrige el acuerdo observado por el acuerdo esperado al azar:
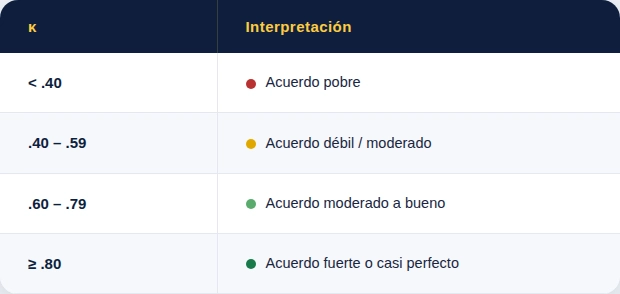
Para decisiones de alto impacto, la literatura recomienda como mínimo κ ≥ .80.
De todos los índices que un proveedor riguroso debe comunicar, el error estándar de medición (SEM) es probablemente el más informativo — y casi nunca aparece en los manuales comerciales.
El SEM indica cuánto se espera que varíe el puntaje observado de una persona alrededor de su puntaje verdadero. Está expresado en las unidades de la escala del test y permite construir intervalos de confianza alrededor de cualquier resultado individual.
¿Por qué importa? Porque sin SEM no es posible saber si la diferencia entre dos candidatos es real o atribuible al error de medición. Dos tests pueden tener el mismo alfa de Cronbach y diferentes SEM. El que reporta SEM permite tomar decisiones informadas; el que no, vende decisiones aparentes.
Si un proveedor no reporta el SEM de su instrumento, no estás comprando un test. Estás comprando un puntaje sin margen de error declarado.
Para tomar decisiones sobre personas — contratar, promover, rechazar — el coeficiente mínimo de confiabilidad aceptado por la literatura académica es 0.90. El reporte sin el error estándar de medición es información incompleta: impide al usuario saber si la diferencia entre dos candidatos es real o ruido de medición.
Esta es la parte difícil de escribir desde dentro, porque exige que apliquemos a nosotros mismos el estándar que hemos descrito para los demás.
Psicotest ha dedicado 15 años a la psicometría aplicada al reclutamiento y ha procesado más de 20 millones de evaluaciones en 25 países. Esa escala — que en sí misma no es evidencia de calidad — sí ha producido algo que sí lo es: un volumen de datos sobre población mexicana y latinoamericana que pocos proveedores en la región pueden equiparar.
Sobre esa base, nuestro compromiso público frente a los criterios desarrollados en este documento es el siguiente:
Y el último punto, que es donde la conciencia técnica se vuelve conciencia ética: cumplimos íntegramente con las cinco leyes mexicanas que aplican al uso de instrumentos psicométricos en contextos laborales — Ley Federal del Trabajo (LFT), Ley Federal de Protección de Datos Personales en Posesión de los Particulares (LFPDPPP), NOM-035-STPS, Ley Federal para la Prevención e Identificación de Operaciones con Recursos de Procedencia Ilícita (LFPIORPI) y Ley Federal para Prevenir y Eliminar la Discriminación (LFPED).
Contratar con ciencia, en el sentido completo del término, es contratar con conciencia. Y ambas dependen, al final, de que el instrumento haya sido construido con la seriedad que esa decisión merece.
Si llegaste hasta aquí, ya estás operando como un decisor informado. El siguiente paso depende de qué tan en serio te tomes la conversación con tu proveedor actual.
Si tienes un proveedor activo, lleva a la próxima reunión las catorce preguntas de la Sección 6 y exige respuestas con evidencia. La reacción te dirá lo que necesitas saber.
Si estás evaluando un nuevo proveedor, consulta el Glosario Psicotest — nuestro repositorio público de definiciones técnicas — y compáralo con la documentación que cualquier proveedor te entregue. La asimetría se nota.
Y si quieres ver cómo se ve un proceso de evaluación construido sobre estos principios, agenda una demo. Sin presión comercial. Aquí lo que vendemos es claridad metodológica.

Referencias
American Educational Research Association, American Psychological Association, & National Council on Measurement in Education. (2014). Standards for educational and psychological testing. American Educational Research Association.
Byrne, B. M., Oakland, T., Leong, F. T. L., van de Vijver, F. J. R., Hambleton, R. K., Cheung, F. M., & Bartram, D. (2009). A critical analysis of cross-cultural research and testing practices: Implications for improved education and training in psychology. Training and Education in Professional Psychology, 3(2), 94-105. https://doi.org/10.1037/a0014516
International Test Commission. (2017). The ITC guidelines for translating and adapting tests (2nd ed.). https://doi.org/10.1080/15305058.2017.1398166
Kane, M. (2013). Validating the interpretations and uses of test scores. Journal of Educational Measurement, 50(1), 1-73. https://doi.org/10.1111/jedm.12000
Ley Federal del Trabajo [LFT], Diario Oficial de la Federación [DOF], 1 de abril de 1970, última reforma DOF 14 de mayo de 2026 (Méx.). https://www.diputados.gob.mx/LeyesBiblio/pdf/LFT.pdf
Ley Federal para Prevenir y Eliminar la Discriminación [LFPED], Diario Oficial de la Federación [DOF], 11 de junio de 2003, última reforma DOF 14 de noviembre de 2025 (Méx.). https://www.diputados.gob.mx/LeyesBiblio/pdf/LFPED.pdf
Messick, S. (1989). Validity. In R. L. Linn (Ed.), Educational measurement (3rd ed., pp. 13-103). American Council on Education/Macmillan.
Nunnally, J. C. (1978). Psychometric theory (2nd ed.). McGraw-Hill.
Prieto, G., & Delgado, A. R. (2010). Fiabilidad y validez. Papeles del Psicólogo, 31(1), 67-74.
Sackett, P. R., Zhang, C., Berry, C. M., & Lievens, F. (2022). Revisiting meta-analytic estimates of validity in personnel selection: Addressing systematic overcorrection for restriction of range. Journal of Applied Psychology, 107(11), 2040-2068. https://doi.org/10.1037/apl0000994
Salgado, J. F., & Moscoso, S. (2008). Selección de personal en la empresa y las administraciones públicas: De la visión tradicional a la visión estratégica. Papeles del Psicólogo, 29(1), 16-24.
Schmidt, F. L., & Hunter, J. E. (1998). The validity and utility of selection methods in personnel psychology: Practical and theoretical implications of 85 years of research findings. Psychological Bulletin, 124(2), 262-274. https://doi.org/10.1037/0033-2909.124.2.262
Society for Industrial and Organizational Psychology. (2018). Principles for the validation and use of personnel selection procedures (5th ed.). American Psychological Association. https://www.apa.org/ed/accreditation/about/policies/personnel-selection-procedures.pdf
Sobre Psicotest
México merece psicometría hecha para México. Durante 15 años hemos estandarizado pruebas psicométricas laborales para el contexto cultural latinoamericano — no para uno importado de hace medio siglo. Más de 20 millones de evaluaciones en 25 países lo respaldan.
No creemos en la psicometría como ritual ni como adorno corporativo. Creemos en ella como ciencia aplicada, con conciencia de quién la usa, para qué se usa y a quién impacta.
Por eso, las empresas que quieren contratar bien, evalúan con ciencia. Y la ciencia, aquí, se llama Psicotest.
Sobre la autora
Aurora Martínez coordina el área de investigación de Psicotest. Lleva más de 10 años trabajando en psicometría aplicada a la selección de personal y su interés principal es que estos conceptos sean comprensibles para quienes toman decisiones, sin perder el rigor que la disciplina exige.
